Mutational grammar fuzzing is a fuzzing technique in which the fuzzer uses a predefined grammar that describes the structure of the samples. When a sample gets mutated, the mutations happen in such a way that any resulting samples still adhere to the grammar rules, thus the structure of the samples gets maintained by the mutation process. In case of coverage-guided grammar fuzzing, if the resulting sample (after the mutation) triggers previously unseen code coverage, this sample is saved to the sample corpus and used as a basis for future mutations.
This technique has proven capable of finding complex issues and I have used it successfully in the past, including to find issues in XSLT implementations in web browsers and even JIT engine bugs.
However, despite the approach being effective, it is not without its flaws which, for a casual fuzzer user, might not be obvious. In this blogpost I will introduce what I perceive to be the flaws of the mutational coverage-guided grammar fuzzing approach. I will also describe a very simple but effective technique I use in my fuzzing runs to counter these flaws.
Please note that while this blogpost focuses on grammar fuzzing, the issues discussed here are not limited to grammar fuzzing as they also affect other structure-aware fuzzing techniques to various degrees. This research is based on the grammar fuzzing implementation in my Jackalope fuzzer, but the issues are not implementation specific.
Issue #1: More coverage does not mean more bugs
The fact that coverage is not a great measure for finding bugs is well known and affects coverage-guided fuzzing in general, not just grammar fuzzing. However this tends to be more problematic for the types of targets where structure-aware fuzzing (including grammar fuzzing) is typically used, such as in language fuzzing. Let’s demonstrate this on an example:
In language fuzzing, bugs often require functions to be called in a certain order or that a result of one function is used as an input to another function. To trigger a recent bug in libxslt two XPath functions need to be called, the document() function and the generate-id() function, where the result of the document() function is used as an input to generate-id() function. There are other requirements to trigger the bug, but for now let’s focus on this requirement.
Here’s a somewhat minimal sample required to trigger the bug:
<?xml version="1.0"?>
<xsl:stylesheet xml:base="#" version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<xsl:value-of select="generate-id(document('')/xsl:stylesheet/xsl:template/xsl:message)" />
<xsl:message terminate="no"></xsl:message>
</xsl:template>
</xsl:stylesheet>
With the most relevant part for this discussion being the following element and the XPath expression in the select attribute:
<xsl:value-of select="generate-id(document('')/xsl:stylesheet/xsl:template/xsl:message)" />
If you run a mutational, coverage guided fuzzer capable of generating XSLT stylesheets, what it might do is generate two separate samples containing the following snippets:
Sample 1:
<xsl:value-of select="document('')/xsl:stylesheet/xsl:template/xsl:message" />
Sample 2:
<xsl:value-of select="generate-id(/a)" />
The union of these two samples’ coverage is going to be the same as the coverage of the buggy sample, however having document() and generate-id() in two different samples in the corpus isn’t really helpful for triggering the bug.
It is also possible for the fuzzer to generate a single sample with both of these functions that again results in the same coverage as the buggy sample, but with both functions operating on independent data:
<xsl:template match="/">
...
<xsl:value-of select="document('')/xsl:stylesheet/xsl:template/xsl:message" />
<xsl:value-of select="generate-id(/a)" />
...
</xsl:template>
This issue also demonstrates how crucial it is for any fuzzer to be able to combine multiple samples in the corpus in order to produce new samples. However, in this case, note that combining the two samples wouldn’t trigger any previously unseen coverage and thus the resulting sample wouldn’t be saved, despite climbing closer to triggering the bug.
In this case, because triggering the bug requires chaining only two function calls, a fuzzer would eventually find this bug by randomly combining the samples. But in case three or more function calls need to be chained in order to trigger the bug, it becomes increasingly expensive to do so and coverage feedback, as demonstrated, does not really help.
In fact, triggering this bug might be easier (or equally easy) with a generative fuzzer (that will generate a new sample from scratch every time) without coverage feedback. But even though coverage feedback is not ideal, it still helps in a lot of cases.
As previously stated, this issue does not only affect grammar fuzzing, but also other fuzzing approaches, in particular those focused on language fuzzing. For example, Fuzzilli documentation describes a similar version of this problem.
A possible solution for this problem would be having some kind of dataflow coverage that could identify that data flowing from document() into generate-id() is something previously unseen and worth saving, however I am not aware of any practical implementation of such an approach.
Issue #2: Mutational grammar fuzzing tends to produce samples that are very similar
To demonstrate this issue, let’s take a look at some samples from one of my XSLT fuzzing sessions:
Part of sample 1128 in the corpus:
<?xml version="1.0" encoding="UTF-8"?><xsl:fallback namespace="http://www.w3.org/url2" ><aaa ></aaa><ddd xml:id="{lxl:node-set($name2)}:" att3="{[$name4document('')att4.|document('')$name4namespace::]document('')}{ns2}" ></ns3:aaa></xsl:fallback>
Part of sample 603 in the corpus:
<?xml version="1.0" encoding="UTF-8"?><xsl:fallback namespace="http://www.w3.org/url2" ><aaa ></aaa><ddd xml:id="{lxl:node-set($name2)}:" att3="{[$name4document('')att4.|document('')$name4namespace::]document('')}{ns2}" xmlns:xsl="http://www.w3.org/url3" ><xsl:output ></xsl:output>eHhDC?^5=<xsl:choose elements="eee" ><xsl:copy stylesheet-prefix="ns3" priority="3" ></xsl:copy></xsl:choose></ddd>t</xsl:fallback>
As you can see from the example, even though these two samples are different and come from different points in time during the fuzzing session, a large part of these two samples are the same.
This follows from the greedy nature of mutational coverage guided fuzzing: when a sample is mutated to produce new coverage, it gets immediately saved to the corpus. Likely a large part of the original sample wasn’t mutated, but it is still part of the new sample so it gets saved. This new sample can get mutated again and if the resulting (third) sample triggers new coverage it will also get saved, despite large similarities with the starting sample. This results in a general lack of diversity in a corpus produced by mutational fuzzing.
While Jackalope’s grammar mutator can also ignore the base sample and generate an entire sample from scratch, it is rare for this to trigger new coverage compared to the more localized mutations, especially later on in the fuzzing session.
One approach of combating this issue could be to minimize each new sample so that only the part that triggers new coverage gets saved, but I observed that this isn’t an optimal strategy either and it’s beneficial to leave (some) of the original sample. Jackalope implements this by minimizing each grammar sample, but stops the minimization when a certain number of grammar tokens has been reached.
Even though this blogpost focuses on grammar fuzzing, I observed this issue with other structure aware fuzzers as well.
A simple solution?
Both of these issues hint that there might be benefits of combining generative fuzzing with mutational fuzzing in some way. Generative fuzzing produces more diverse samples than mutational fuzzing but suffers from other issues such as that it typically generates lots of samples that trigger errors in the target. Additionally, as stated previously, although coverage is not an ideal criteria for finding bugs it is still helpful in a lot of cases.
In the past, when I was doing grammar fuzzing on a large number of machines, an approach I used was to delay syncing individual fuzz workers. That way, each worker would initially work with its own (fully independent) corpus. Only after some time has passed, the fuzzers would exchange sample sets and each worker would get the samples that correspond to the coverage this worker is missing.
But what to do when fuzzing on a single machine? During my XSLT fuzzing project, I used the following approach:
-
Start a fuzzing worker with an empty corpus. Run for T seconds.
-
After T seconds sync the worker with the fuzzing server. Get the missing coverage and corresponding samples from the server. Upload any coverage the server doesn’t have (and the corresponding samples) to the server.
-
Run with combined corpus (generated by the worker + obtained from the server) for another T seconds.
-
Sync with the server again (to upload any new samples) and shut down the worker.
-
Go back to step 1.
The result is that the fuzzing worker spends half of the time creating a fully independent corpus generated from scratch and half of the time working on a larger corpus that also incorporates interesting samples (as measured by the coverage) from the previous workers. This results in more sample diversity as each new generation is independent from the previous one. However the worker eventually still ends up with a sample set corresponding to the full coverage seen so far during any worker lifetime. Ideally, new coverage and, more importantly, new bugs can be found by combining the fresh samples from the current generation with samples from the previous generations.
In Jackalope, this can be implemented by first running the server, e.g.
/path/to/fuzzer -start_server 127.0.0.1:8337 -out serverout
And then running the workers sequentially with the following Python script:
import subprocess
import time
T = 3600
while True:
subprocess.run(["rm", "-rf", "workerout"])
p = subprocess.Popen(["/path/to/fuzzer", "-grammar", "grammar.txt", "-instrumentation", "sancov", "-in", "empty", "-out", "workerout", "-t", "1000", "-delivery", "shmem", "-iterations", "10000", "-mute_child", "-nthreads", "6", "-server", "127.0.0.1:8337", "-server_update_interval", str(T), "--", "./harness", "-m", "@@"])
time.sleep(T * 2)
p.kill()
Note that Jackalope parameters in the script above are from my libxslt fuzzing run and should be adjusted according to the target.
Additionally, Jackalope implements the -skip_initial_server_sync flag to avoid syncing a worker with the server as soon as the worker starts, but this flag is now the default in grammar fuzzing mode so it does not need to be specified explicitly.
Does this trick work better than running a single uninterrupted fuzzing session? Let’s do some experiments. I used an older version of libxslt as the target (libxslt commit 2ee18b3517ca7144949858e40caf0bbf9ab274e5, libxml2 commit 5737466a31830c017867e3831a329c8f605c877b) and measured the number of unique crashes over time. Note that while the number of unique crashes does not directly correspond to the number of unique bugs, being able to trigger the same bug in different ways still gives a good indication of bug finding capabilities. I ran each session for one week on a single machine.
I ran two default experiments (with a single long-lived worker) as well as the two experiments with the proposed solution with different values of T, T=3600 (one hour) and T=600 (10 minutes).
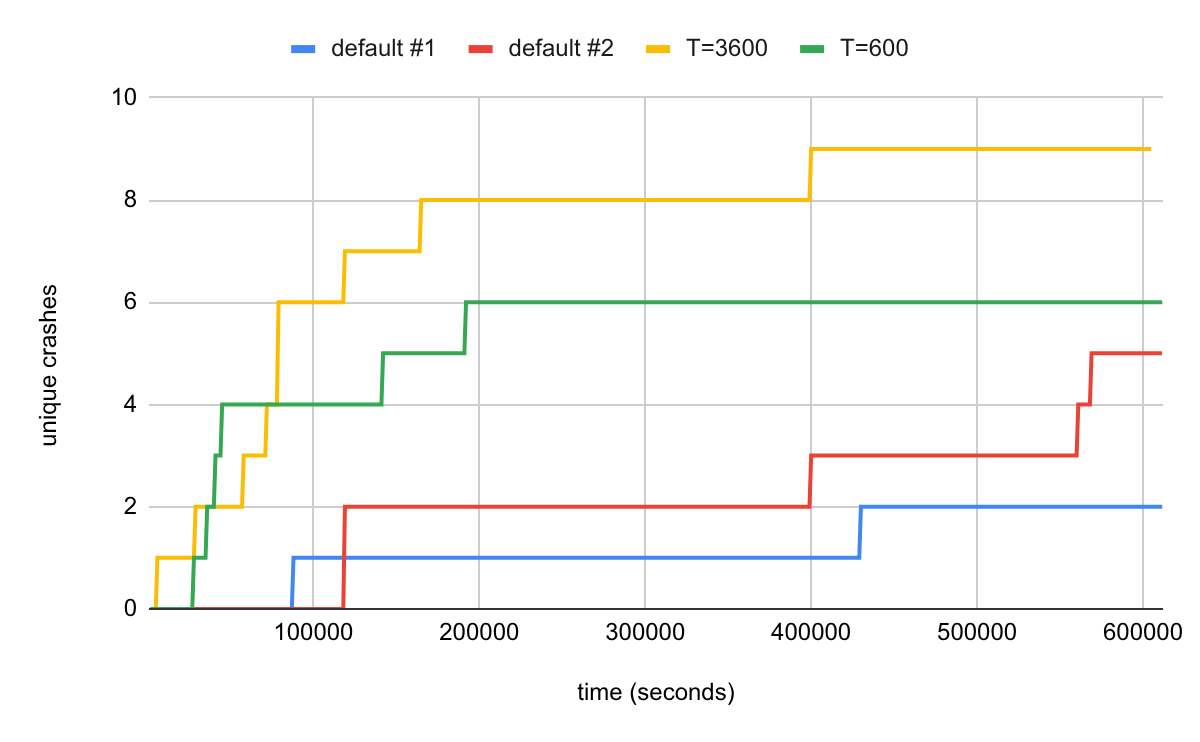
As demonstrated in the chart, restarting the worker periodically (but keeping the server), as proposed in this blog post, helped uncover more unique crashes than either of the default sessions. The crashes were also found more quickly. The default sessions proved sensitive to starting conditions where one run discovered 5 but the other run only 2 unique crashes during the experiment time.
The value of T dictates how soon a worker will switch from working on only its own samples to working on its own + the server samples. The best value in the libxslt experiment (3600) is when the worker already found most of the “easy” coverage and discovered the corresponding samples. As can be seen from the experiment, different values of T can produce different results. The optimal value is likely target-dependent.
Conclusion
Although the trick described in this blogpost is very simple, it nevertheless worked surprisingly well and helped discover issues in libxslt quicker than I would likely be able to find using default settings. It also underlines the benefits of experimenting with different fuzzing setups according to the target specifics, rather than relying on tooling out-of-the-box.
Future work might include researching fuzzing strategies that favor novelty and would e.g. replace samples with the newer ones, even when doing so does not change the overall fuzzer coverage.